While we try to keep things accurate, this content is part of an ongoing experiment and may not always be reliable.
Please double-check important details — we’re not responsible for how the information is used.
Biochemistry Research
Uncovering the Hidden Threat: Century-Old Clues Reveal Genetic Erosion in Australia’s Iconic Songbird
A hidden threat facing one of Australia’s most iconic birds has been uncovered in a new study. The critically endangered regent honeyeater once numbered in the hundreds of thousands, but their population has dwindled to fewer than 300. By analysing the DNA of museum specimens more than 100 years old and comparing it to modern samples, the team discovered that despite a population decline of 99 per cent, this has not been entirely mirrored by genetics. The bird has lost 9 per cent of its genetic diversity.











Biochemistry Research
“Unlocking Timekeeping Secrets: Scientists Reveal How Artificial Cells Can Accurately Keep Rhythm”
Scientists at UC Merced have engineered artificial cells that can keep perfect time—mimicking the 24-hour biological clocks found in living organisms. By reconstructing circadian machinery inside tiny vesicles, the researchers showed that even simplified synthetic systems can glow with a daily rhythm—if they have enough of the right proteins.
Behavioral Science
The Sugar that Sparked Life: Unraveling the Mystery of Ribose’s Preeminence in RNA Development
What made ribose the sugar of choice for life’s code? Scientists at Scripps Research may have cracked a major part of this mystery. Their experiments show that ribose binds more readily and selectively to phosphate compared to other similar sugars, forming a structure ideal for RNA formation. This discovery hints at how nature might have selected specific molecules long before enzymes or life existed, and could reshape our understanding of life’s chemical origins.

Biochemistry Research
The Whispering Womb: Uncovering the Secret Language of Embryonic Cells
Scientists found that embryonic skin cells “whisper” through faint mechanical tugs, using the same force-sensing proteins that make our ears ultrasensitive. By syncing these micro-movements, the cells choreograph the embryo’s shape, a dance captured with AI-powered imaging and computer models. Blocking the cells’ ability to feel the whispers stalls development, hinting that life’s first instructions are mechanical. The discovery suggests hearing hijacked an ancient force-sensing toolkit originally meant for building bodies.

A New Horizon for Vision: How Gold Nanoparticles May Restore People’s Sight

Revolutionizing Quantum Communication: Direct Connections Between Multiple Processors

Retiring Abroad Can Be Lonely Business
Harnessing Water Waves: A Breakthrough in Controlling Floating Objects

Household Electricity Three Times More Expensive Than Upcoming ‘Eco-Friendly’ Aviation E-Fuels, Study Reveals

“Unveiling Hidden Patterns: A New Twist on Interference Phenomena”
Reducing Falls Among Elderly Women with Polypharmacy through Exercise Intervention
-
 Detectors1 year ago
Detectors1 year agoA New Horizon for Vision: How Gold Nanoparticles May Restore People’s Sight
-
Cancer1 year ago
Revolutionizing Quantum Communication: Direct Connections Between Multiple Processors
-
Earth & Climate1 year ago
Retiring Abroad Can Be Lonely Business
-
Albert Einstein1 year ago
Harnessing Water Waves: A Breakthrough in Controlling Floating Objects
-
Earth & Climate1 year ago
Household Electricity Three Times More Expensive Than Upcoming ‘Eco-Friendly’ Aviation E-Fuels, Study Reveals
-
Chemistry1 year ago
“Unveiling Hidden Patterns: A New Twist on Interference Phenomena”
-
Diseases and Conditions1 year ago
Reducing Falls Among Elderly Women with Polypharmacy through Exercise Intervention
-
Earth & Climate1 year ago
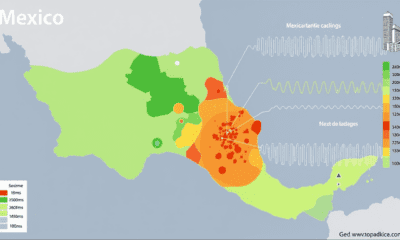
Predicting Damage from Local Earthquakes in Mexico City